
Managing Change–Cisco Managing Networks
Change management is the set of formal and informal processes used to manage changes to a network over time. Change management plans have many components, including
• Testing processes that must be followed before network changes can be implemented.
• Documentation standards, including the problem being solved, how it is being solved, why it is being solved this way, expected changes in behavior, etc.
• A backout plan in case a change fails.
A backout plan is a simple set of instructions allowing the operator to quickly and easily restore the network to its original, pre-change state.
Changes sometimes occur during scheduled outages, where the network is intentionally taken down to make changes, test the changes, and then be brought back into service. These scheduled outages are also called change windows.
Most modern networks do not have networkwide scheduled outages. Instead, outages are planned for individual modules.
Testing Techniques
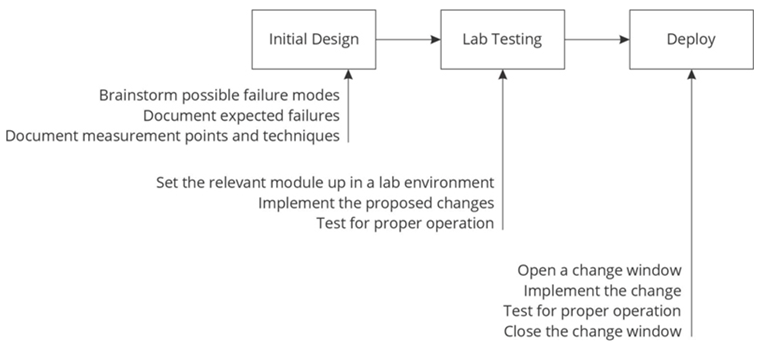
Network engineers often understand tests across multiple stages, but only at a surface level. Figure 21-3 illustrates the different places testing might take place in design and deployment.
Figure 21-3 Change Process Example
Many operators test only for proper operation.
Proper operation testing validates the system produces expected outputs when given expected inputs. This kind of testing is also called positive testing because it checks for proper operation only when all the system’s components are working correctly, and it checks system operation using only expected inputs.
Organizations should strive to extend this kind of positive testing to much stronger forms of negative testing. Negative testing includes intentionally failing individual pieces of hardware and software, misconfiguring devices, injecting bad control plane information, running attacks against the network, etc.
Negative testing can
• Catch failure modes no one thought of in the design phase.
• Help operators gain a better understanding of how the network normally looks versus how it looks in a failed state.
• Find measurements that would be useful in a failure but are not captured in the initial design.
Injecting failures into a network under test or an operational network is called chaos engineering. Many engineers and operators fear to inject failures; they fear the network will fail.
That, however, is the point.
A second concept in testing is called the canary. A canary test places a small amount of real-world workload after a change, putting the changes into operation when the operator is confident the network will work correctly with the changes in place. The name comes from the canaries miners used to carry into mines. If you are in a mine with a canary and the canary passes out, it is time to leave; canaries will run low on oxygen and pass out far more quickly than humans.
Figure 21-4 illustrates a single module’s complete change control process within a larger network.
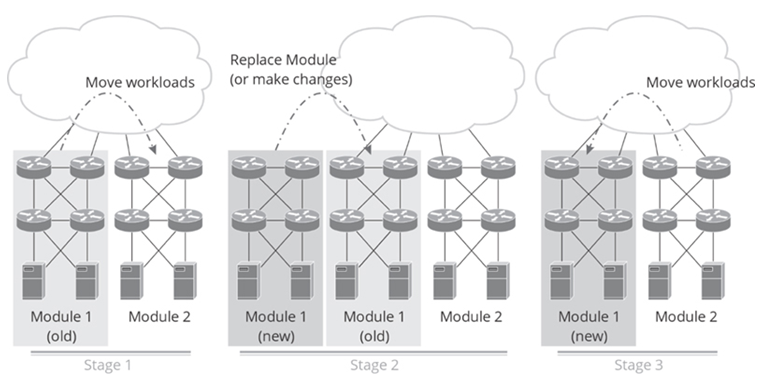
Figure 21-4 Deployment Process Example
In Stage 1:
• A modified module is designed, emulated in a lab environment, and tested using positive and negative testing.
• A physical replacement module is built, or automation is created to move the module from an old configuration to a new one, etc.
• The change window is opened. If applications and users can be moved without disruption (which is ideal), no change window or network outage is needed.
• All processes and users are moved off Module 1 and onto Module 2.
In Stage 2:
• The old Module 1 is removed from the network and replaced by the new version. If this is just a software or configuration change, the automation system is instructed to make the correct changes.
• Positive and negative testing is performed on the new module. This should include chaos, security, and other kinds of testing.
• Engineers should observe the results of this testing for any signs the new design does not work, and to gather information about what failures look like, etc.
• If this testing works, the change window can be closed at this point. While the new Module 1 has no workload, the network can be considered “operational” now.
In Stage 3:
• A few applications or users are moved into the new Module 1.
• If these applications migrate successfully, the remaining applications and users can be migrated to the new Module 1, restoring the network to its original operating condition (with modifications)
This short section gives you a brief overview of the canary process. Many other elements are not considered here, such as setting clear guidelines about when one stage ends and another begins, documentation that must exist before undertaking the canary deployment, how to control module generations, etc.