
Fragility and Resilience–Cisco Troubleshooting
Fragility and resilience can be described in two statements:
• Fragile systems fail easily in the face of environmental pressure.
• Resilient systems survive environmental pressure.
Environmental pressure might be a link failure, software failure, hardware failure, or even human error.
Network engineers primarily rely on redundancy to increase resilience by eliminating single points of failure. Figure 22-2 illustrates redundancy.
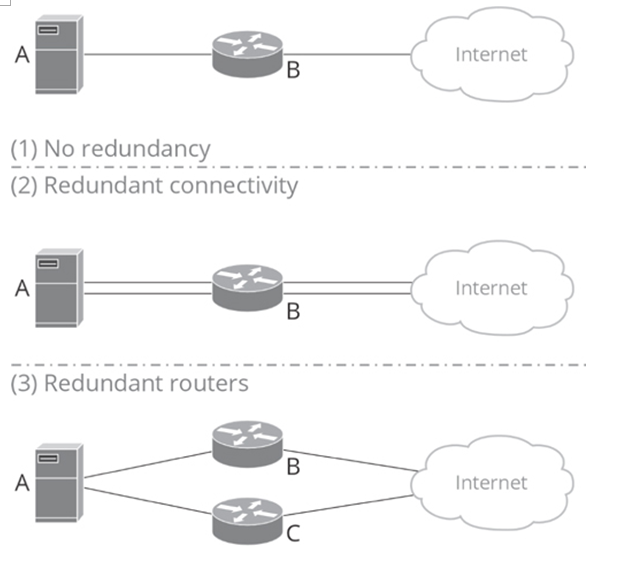
Figure 22-2 Redundancy in Network Design
Figure 22-2 shows the same network with different levels of redundancy:
1. Three single points of failure: server A’s network connection, router B, and router B’s connection to the Internet
2. One single point of failure: router B
3. No single points of failure
Redundancy is adding network capacity in parallel with existing capacity so the network can route through an alternate path in the case of failure.
A single point of failure is where a link or device failing prevents the network from forwarding traffic.
If you can increase resilience by adding more paths in parallel, why not add enough to support any conceivable failure scenario? For example, some network engineers will build enough redundancy to prevent double or triple points of failure from impacting network performance.
In some cases, additional redundant links are too expensive.
Each additional path costs the same amount but adds less additional resilience. A good rule of thumb is
• Adding a second path increases resilience by about 50% over the single path.
• Adding a third path increases resilience by about 25% over two paths.
• Adding a fourth path increases resilience by about 12% over three paths.
In most situations, two paths are adequate. There are almost no situations where four paths are required to provide good network resilience.
Each additional path adds to network complexity, slowing the network’s reaction to failures. Networks with too many redundant paths can perform more poorly than a simpler design with just a few parallel paths.
Shared fate is another problem engineers need to plan around.
Shared fate exists when a single resource’s failure can cause some other group of devices to fail. Figure 22-3 illustrates shared fate.
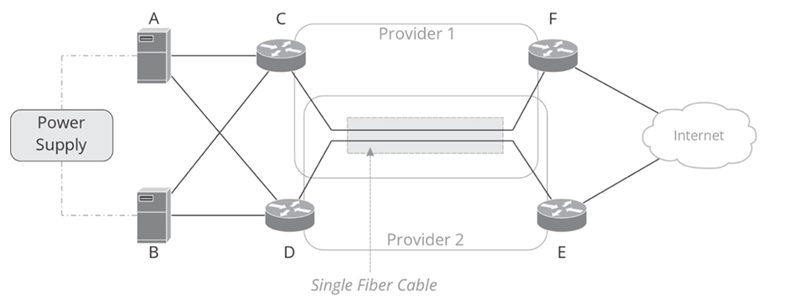
Figure 22-3 Shared Fate
The operator designed and built the network in Figure 22-3 so there would not be any single points of failure. From the operator’s perspective, there are two servers, each connected to a separate path to the Internet.
The operator might not know there are still two single points of failure in this network. The first single point of failure is the power supply supporting servers A and B. If this single power supply fails, servers A and B will fail, so server A shares fate with server B. The two links to the Internet also share fate at a single point of failure because both providers have chosen to carry traffic through different wavelengths on the same fiber cable.
It is almost impossible to remove every instance of shared fate from a network design, but engineers should be aware of the problems shared fate can cause and avoid it where possible.
Troubleshooting Tools and Techniques
If networks never failed, engineers would not need troubleshooting tools, but networks do break, so engineers need to be able to troubleshoot failures quickly.
The most effective troubleshooting technique blends start with what you know with a more formal half-split method. Once you find the problem, you need to decide how to fix it and then review what happened, why, how you (or you and your team) did troubleshooting the problem, and how you can improve your troubleshooting performance in the future.