
Technical Debt–Cisco Managing Networks
One term you are bound to hear a lot if you work around engineers is technical debt. Most engineers think of technical debt as some combination of the following:
• Anything old hardware, software, or system
• Anything the original vendor no longer supports
• Anything they do not understand
The original meaning of technical debt is the buildup of changes in a system over time no one really understands or the gap between how a system works and how the operator thinks it works. When you have 10 or 15 people designing and deploying changes to a large network or making changes to an application’s code, it is easy to lose sight of the system’s design.
Engineers resolve technical debt through refactoring or the intentional rebuilding of system components to fit current requirements, specifications, and testing practices.
For an application, refactoring might mean rewriting the entire application or maybe rewriting pieces of the application so smaller changes fit into a new architectural vision. For a network, refactoring can mean anything from removing older hardware and software to reworking the configuration on every device to fit a new architectural pattern.
Management Challenges
Network management is often difficult in small- and large-scale networks because problems are not always obvious. As RFC
1925m, rule 4 says: “Some things in life can never be fully appreciated nor understood unless experienced firsthand.”
This section considers two challenges: the observability problem and the law of large numbers.
The Observability Problem
Physicists and scientists know observing things at a very small scale changes their behavior. In quantum mechanics, this is stated as Heisenberg’s Uncertainty Principle, which says there is a fundamental limit to the accuracy of measuring specific pairs of physical properties.
The best-known physical properties are momentum and position. Measuring the momentum of a particle changes its position, and measuring the position of a particle changes its momentum.
Does this apply at a larger scale, say in a network or software?
Yes.
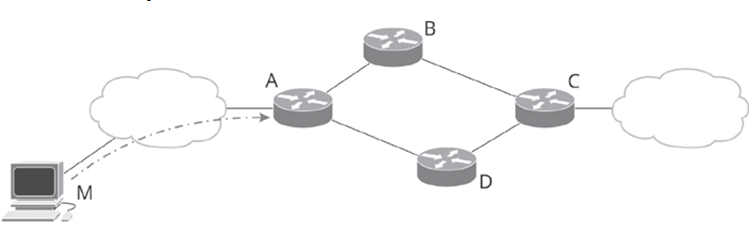
The observability problem is the impact of the network’s operation because you are trying to measure something about the network. For example, assume you are having problems with a particular router, so you set up a monitoring host in the network, as shown in Figure 21-5.
Figure 21-5 The Observability Problem
In Figure 21-5, host M is configured to capture router A’s input queue every time the queue holds 10 packets (the input queue depth is 10 packets). Consider what happens when the 10th packet is placed in the input queue:
• Host M sends a packet to A, running the correct command to display the queue.
• Router A sends the information host M requested.
• Host M acknowledges receiving this information.
If host M is connected through the monitored port, M’s packets will count toward the number of packets in A’s input queue, which means sometimes M will send information when only nine “real” packets are in its input queue. Further, host M’s packets will be included in M’s response.
Checking the contents of the input queue is an obvious case where observing a network changes the network’s behavior.
Many others are not so obvious. Configuring debug output can cause an application to run more slowly, resolving a problem or changing the symptoms.
Two rules can help you counter the observability problem:
• Always ask, “How could measuring this change the measurement?” Try to work around projected changes.
• Always instrument the network so you can measure it at any time but keep measurements to the minimum unless you need them.
Failure Rates in the Real World
Computer and network equipment manufacturers perform rigorous lab testing to determine how long a device should last before failing. This number is called the mean time between failures (MTBF). For instance, the Cisco 8200 Series Edge Platform has an MTBF of 692,577 hours, or around 80 years. If you install devices that will not fail for 80 years, you should never experience a hardware failure.
Things do not work out this way in the real world.
First, each router, switch, or other network device has optical interfaces, memory modules, and many other components.
Each of these also has MTBF ratings; one component failure will cause the entire device to fail. The MTBF of each device component must be combined to understand just how often a device might fail.
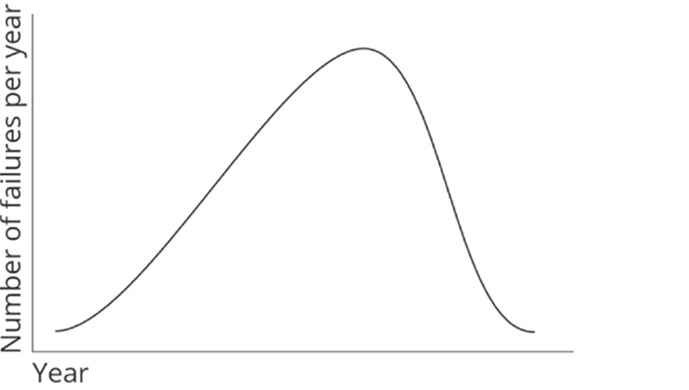
Second, at some scale, the law of large numbers will overcome even the longest MTBF. If you have 80 Cisco 8200s in your network, one will fail annually across 80 years. They might all fail in the 80th year, or one a year might fail for 80 years. Figure 21-6 shows the most likely failure rate, a skewed bell curve.
Figure 21-6 Probable Failure Rates
While the top of this curve might seem distant, some routers will still fail each year. At higher scales, more routers will fail each year.
Finally, any time humans interact with physical objects, there is always some chance a little too much pressure over there, or a little too much pressure over there, will cause a weak connection or physical component. Humans also conduct high voltages along their skin through static electricity.
Electrostatic discharge (ESD) procedures are designed to drain static electricity off the human body and tools to prevent damage to electronic components. However, even the strictest adherence to ESD processes still leaves some room for weakening a component, reducing the time before it fails.
As the volume of hardware increases, the number of human-to-hardware interactions increases, causing more ESD failures.